
近日,我中心2015级博士生余丽珊以第一作者的身份撰写的论文“Developing an automated mechanism to identify medical articles from Wikipedia for knowledge extraction”被医学信息学期刊International Journal of Medical Informatics接收并在线发表。论文指导教师为中心俞声副教授。
信息化是自动化发展的前提,医疗领域的信息化如对医疗相关信息的整理汇总,对医疗资源的管理和临床决策支持的自动化开发等具有重要意义。从海量的信息中及时获取医学相关信息对医疗人工智能的发展亦至关重要。维基百科是医学信息研究领域的主要信息源之一。建立维基百科的医学信息自动提取机制,以获取其中医学实体概念相关的词条和关系事实等结构化信息是具有挑战性的,并且随着维基百科规模的扩大和词条质量的提高,该自动提取机制所获取的医学信息也将越来越丰富和准确。
有七类医学范畴对人类健康非常重要。本文的目的是通过机器学习算法从维基百科中自动识别解剖、药物、医疗设备、疾病症状、细菌寄生虫、生理和手术这七类医学文章,获取维基百科中的医学实体概念及维基百科和Wikidata中关系事实等结构化信息。然而,该识别任务缺少文章及其语义所属类别(对应于七类医学范畴)的标注集作为机器学习算法的训练集。此外由于各类别文章在维基百科中极低的占比,导致分类任务样本极度不平衡从而影响分类算法的学习。
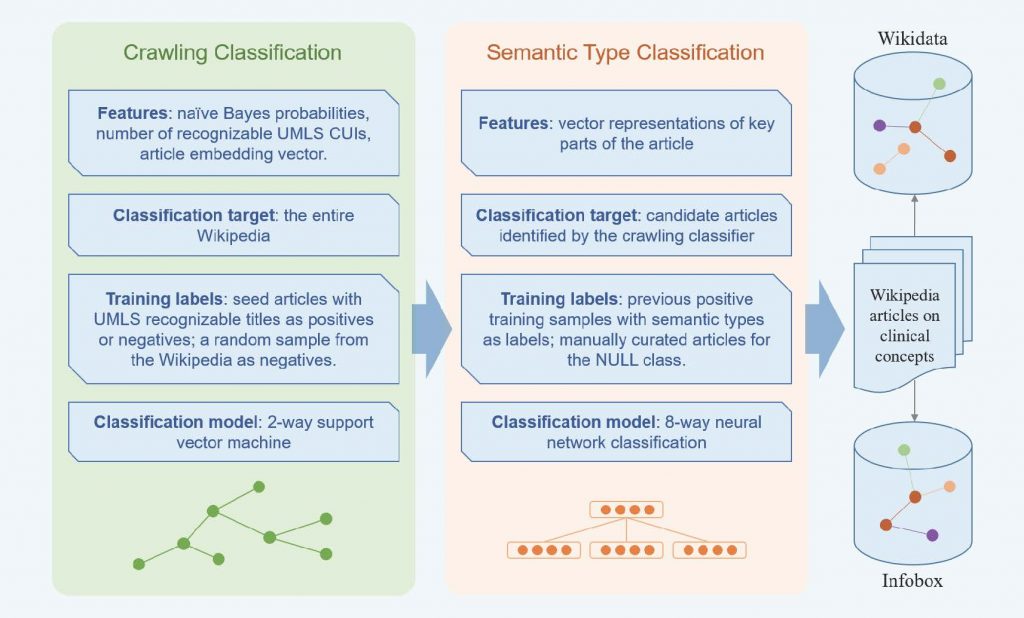
为了解决此问题,作者通过利用现有成熟的医学知识库UMLS(一体化医学语言系统)对维基百科中文章概念进行语义类别匹配,从而获取了一定数量的七种语义类别维基百科文章作为训练集;并基于维基百科中丰富的结构信息,提出了二阶段分类模型:(1)发展爬虫分类策略进行医学相关文章的识别,获取尽可能多的医学文章从而避免数据极度不平衡情况;(2)建立深度学习分类模型,对所识别出文章进行七类语义类别的识别,并根据这些结果在维基百科页面中的消息盒(Infobox)和Wikidata系统中提取关系事实等结构化信息。本文对最终结果进行了评估,并预留部分标注集作为测试集评估模型的识别表现(准确率和召回率),同时也抽取部分识别结果进行人工检验。
通过结果评估以及与基准模型的对比,该自动识别机制具有高准确率和高召回率的整体识别能力以及低的假医学文章发现率。该系统在Wikidata/Infobox上提取了相关医学概念的结构化信息,分析得到的结构化信息也能给UMLS中的医学疾病关系有很好的补充。此研究工作定期使用该自动提取机制识别维基百科中的医学文章及其结构化信息并将其公布,为相关领域学者的科学研究提供了数据基础;该工作对于其他领域相关文章及词条等信息的提取也具有参考意义。