
近日,我中心2017级博士研究生袁正以第一作者身份撰写的论文 “Unsupervised multi-granular Chinese word segmentation and term discovery via graph partition” 被Journal of Biomedical Informatics (Health Informatics Q1,Computer Science Applications Q1) 接收并在线发表。该论文是作者同清华大学刘元昊、尹秋阳、李铂垚同学、北京清华长庚医院冯晓彬教授以及江苏卫健委张国明共同完成,我中心俞声副教授是论文的通讯作者。
电子病历蕴含丰富的医学信息,对生物医学研究、公共卫生统计、卫生经济学、医学人工智能等诸多领域具有重要的价值。为了进行电子病历分析,首先需要进行分词和术语发现。但由于缺少完善的中文医学词典和已分词的中文电子病历,有监督的分词算法难以训练,已有的中文分词系统在中文电子病历的应用中表现不好。基于此种情况,作者以图分割为基础,提出全新的无监督的多粒度中文分词和术语发现的方法。
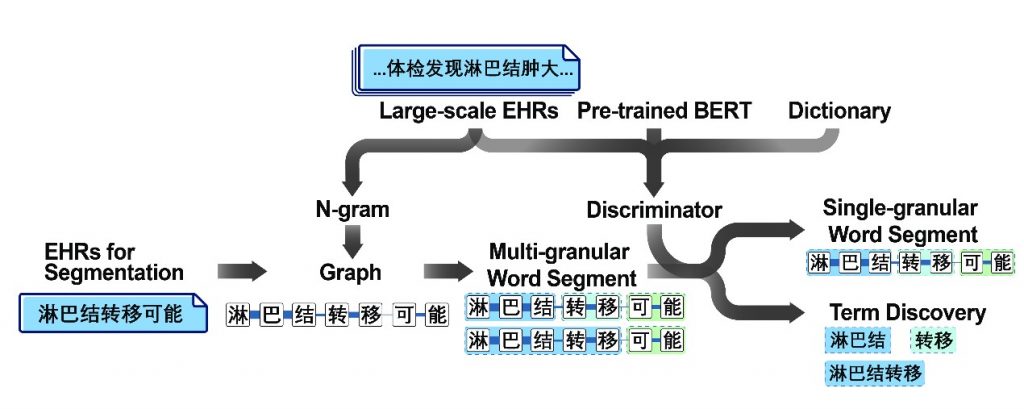
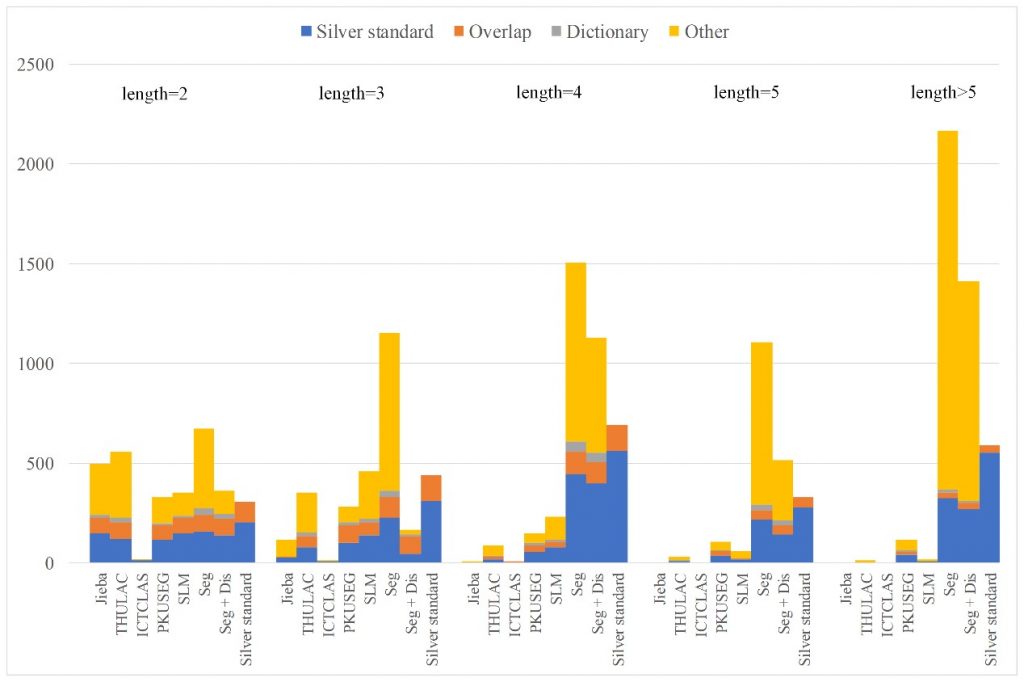
论文将分词问题转换为图的分割问题:将一个句子转换为无向图,顶点为每个字符,边的权重通过n-gram统计量计算,通过不同粒度的图分割获得了多粒度的分词结果。论文提出了一个术语判别系统,并训练BERT分类器以判断该术语是否被正确分词。该术语判别系统可以在已有的多粒度分词结果上提取正确的医学术语进行术语发现。该方法在CCKS中文病历数据集上的术语发现任务中表现遥遥领先已有的中文分词系统。
论文网页: