本文选自清华大学统计学研究中心开设的统计学辅修课程《数据挖掘中的统计方法》优秀学生成果。
小组成员:
高代玘:清华大学工业工程系 14级本科生
谢禹晗:清华大学工业工程系 14级本科生
指导教师:俞声
1 背景介绍
对商品评论做文本分析有很多现实意义。对公司来说,一方面可以通过顾客的意见帮助公司发现自己的核心竞争力和弱势,同时也可以发现公司竞争对手的优势。对顾客来说,顾客可以参考其他顾客的评论对其是否购买商品做决定。
情感分析(SA)又称为倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,其中情感分析还可以细分为情感极性(倾向)分析,情感程度分析,主客观分析等。情感极性分析的目的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
本次研究中,我们使用基本统计学和机器学习方法对亚马逊食品评论数据集做情感分析。
2 数据集介绍
我们的是从Kaggle网站上下载的数据集。数据集原始发布在SNAP上。数据集中共包含568,454条数据。
我们提取数据集中的“分数”和“总结”两项进行后续分析。“分数”代表评论中用户给商品的打分,分数范围为1-5。“总结”是用户评论的简要总结文本。
3 研究意义
对食品短评数据集进行情感分析有较强的现实意义。现在微信朋友圈、推特等大量社交平台的“状态”都是短评的形式;“民以食为天”,食品又是大家比较关注的话题,社交平台上有很多关于食品的“感叹”或“吐槽”。通过对本数据集的研究,我们希望可以将其应用拓展到其他关于食品的短评上。
4 数据探索
- 对于文本处理的启发
我们随机选取打分为1-5的评论各10000条,对文本进行基本的去标点,小写化和去停词的基本处理后统计词频,制作词云图。我们发现打分为1分的词云图中有很多正向情感词汇,如“like”,”good”。

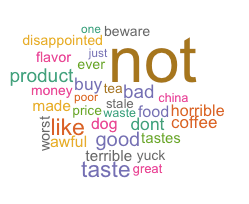
我们重新审视数据集发现打分为1分的评论中确实常常含有正向词汇,但这些词汇往往是跟在“not”这类否定副词后面。英文的停词表中去除了“not”等一些否定副词,我们在去停词时恢复了这类否定停词,重新制作打分为1的词云图,我们发现词频最高的词变为了“not“,符合我们的预期。

- 对于标签划分的启发
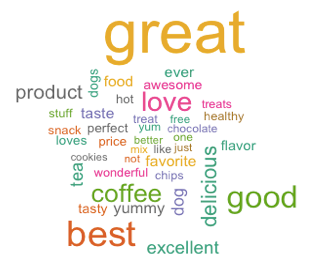
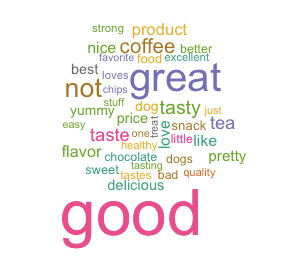
我们希望把打分为1-5的评论划分为两类。依据尝试,我们假设打分为1,2分的评论大多为负向情感评论,假设打分为4,5的评论大多为正向情感评论。但是对于评分为3分的评论的划分是很难界定的,所以我们从词云图中寻找部分启发。评论打分为1到5分的词云图如下图所示,我们可以发现对于打分为1,2,4,5的评论的假设符合我们的假设。打分为3分的评论词频最高的词为“not“,所以我们认为3分评论应归类到负向评论中。


5 数据基本处理
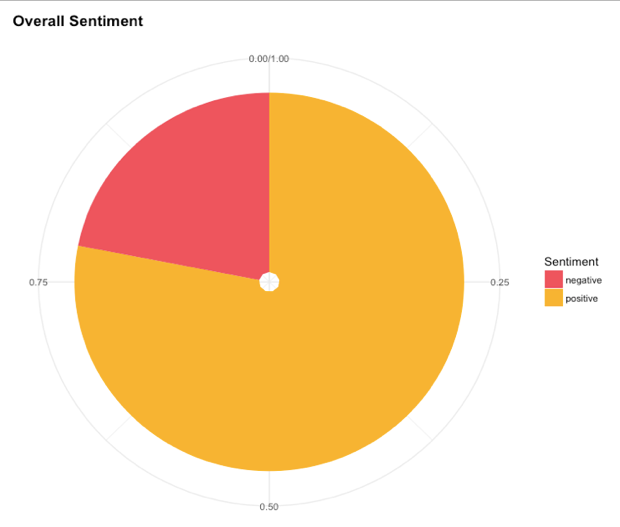
我们依据上述划分方法将数据集划分为打分为4,5的正向情感评论和打分为1,2,3的负向情感评论。经统计,原始数据集中有大约22%的负向情感评论和78%的正向情感评论。饼状统计图如下图所示:
我们认为数据集样本量可能超出我们的电脑运行允许范围,并且正负情感评论数目不均衡,我们选取数据集的子集进行分析。我们最终随机选取正负情感评论各10000条。依据数据探索中的经验,我们对新的数据集文本进行去标点,去停词,小写化等基本处理。此后,我们对正负情感评论分别做层次聚类和Kmeans聚类。下图展示负向情感评论的聚类结果。
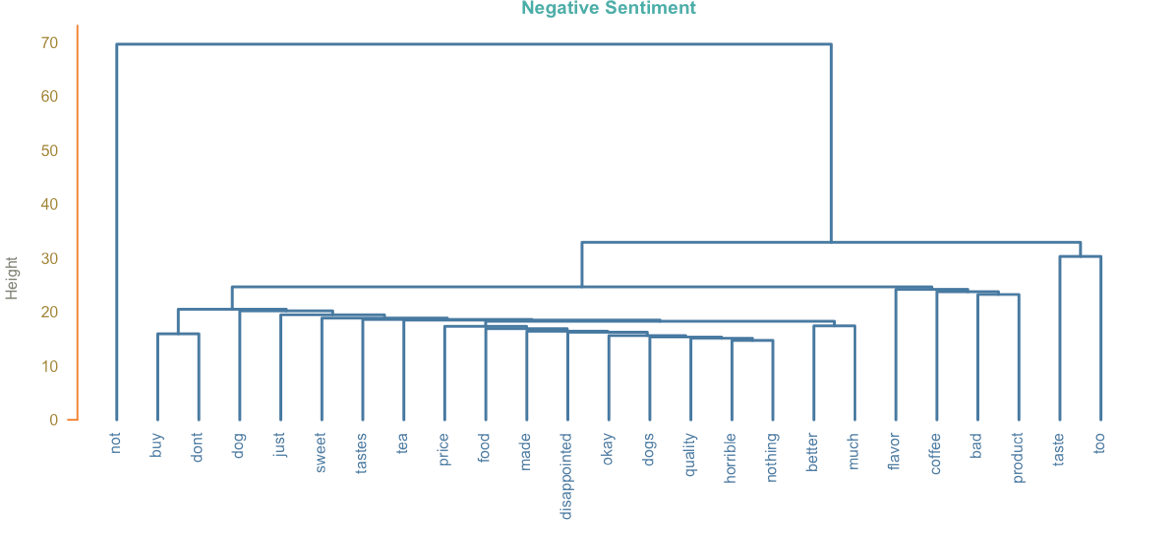
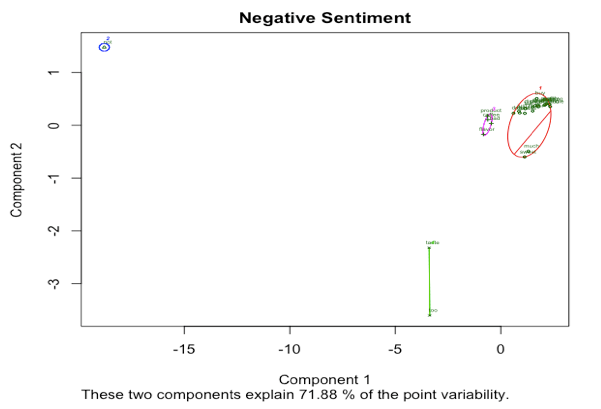
从两种聚类方式的结果中我们发现,两种聚类结果相似,且都将“not“ 单独分为一类,但是我们发现在Kmeans聚类过程中“taste”和“tastes”没有被分为一类,结果不够理想。我们认为,在后续处理中,我们应考虑将文本进行主干化处理。
简言之,我们在上述探索过程中对文本处理有了新的认识,我们将以上经验运用到了后续处理和建模过程中。
6 数据清洗
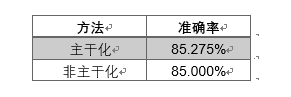
基于以上分析,我们对每个词都进行了主干化,即去除前缀、后缀,将词末尾的y都替换成i等,这样可以使得同词根的不同词都变成同一种形式(不一定是词根的形式),如“tastes”变为“taste”, “potential”变为“potent”。否则,每种词都以不同的形式出现,但是实则表达的是同一含义;而由于出现频率不同,经过计算之后两个词的相似度可能会变低,影响分析的准确性。我们使用逻辑回归的分类方法进行了验证,发现主干化确实能在一定程度上提高准确率。
经过以上三种处理,即小写化、去标点及主干化,我们得到的短评变成了如下形式: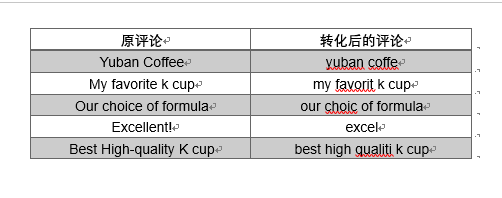
7 将文本转化为向量
词嵌入是指将一个单词转化为一个向量的过程,常见方法有One-hotRepresentation、Word2vec、TFIDF等。One-hot Representation将一个词转化为一个很长的向量,每一维代表一个词,只有这个词的位置是1,其余都是0。Word2vec通过词的出现频率和位置等计算出一个较低维的向量,用向量空间上的相似度来体现词的相似度。TFIDF在计算每个词在本文中出现的频率的同时,还考虑了在所有文章中的频率,以弱化常用词的重要程度。
7.1 Word2vec
我们首先尝试了Word2vec方法,但是结果并不理想,各种分类器的准确率都接近与随机分类。我们观察了几个情感词最相似的词及他们的相似程度:
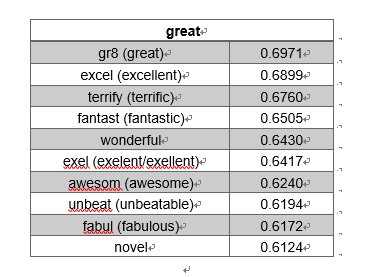
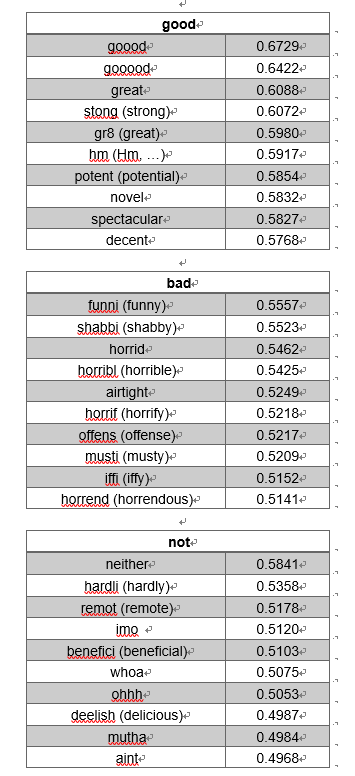
可以发现,“great”所表达的情感要比“good”强烈一些,从最相近的词可以看出来。“bad”与“horrible”的几个衍生词都比较相近。“not”与一些负面的副词较为相近。
但是同时我们看到,Word2vec事实上并不能区分同一类词的正负含义,计算可得:
即“good”和“bad”的相似度达到了45.35%。由此,我们发现了Word2vec在情感分析中不可用的原因。
7.2 TFIDF
基于此,我们尝试了另一种方法,即TFIDF,将每一篇文章(在本文中是一句短评)转化为一个向量。TFIDF由两部分组成,TF表示的是这个词在文中出现的频率,IDF表示的是这个词在所有文章中出现频率的倒数。只有这两部分的值都较高时,我们才可以认为这个词在本文中经常出现,但是在其它文章中不常出现,因此对本文有较强的代表性。
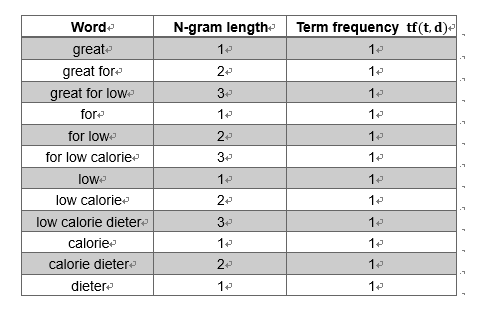
不过此处所说的“词”并不一定是一个单词,也可能是一个词组,这种方法称为“n-gram”,词组的大小可以自行确定。当我们设定了词组的上下界时,所有长度在上下界之间的连续出现的几个词都将被作为单独的“词”进行计数。例如,当n-gram的范围为时,文本“great for low calorie dieter”包含的词组及出现频率为:
不同的上下界对准确率也会有影响,我们使用了逻辑回归进行测试:
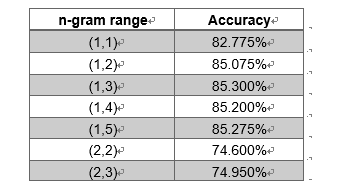
可以看到,当下界为2时,我们忽略了所有单个词本身,但是显然丢失了很多信息。我们对下界为1的5种n-gram的准确率画图可以得到:
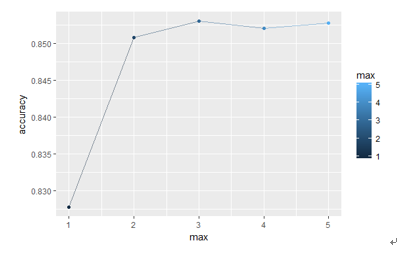
可以看出,仅包含单个单词的准确率较低,说明相连的几个词可以表示文章的语境含义,可以提高准确率。至于上界是几,则差别不大。
最后,为了使得不同长度的词不会因为句子本身的大小而产生过大差别,将表示这句话的向量进行了标准化,及将这个向量的欧式距离标准化为1。
8 模型拟合及预测
8.1 数据集划分及交叉验证
我们将数据集按8:2的比例划分为了测试集和验证集。并且此划分在使用各种分类器的时候保持固定,以直接对比不同方法在相同数据集上的准确率。
我们针对每种方法都进行了调参,使用5折交叉验证在训练集上选择了最佳参数。
最后,拟合好的模型分别放到测试集上进行准确率的验证,以找到最佳方法。
8.2 方法对比及分析
我们分别使用了一下7种方法进行分类,准确率如下:
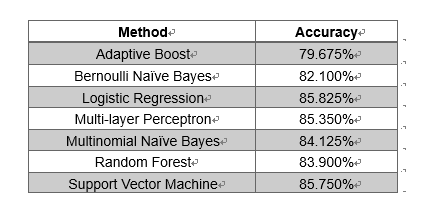
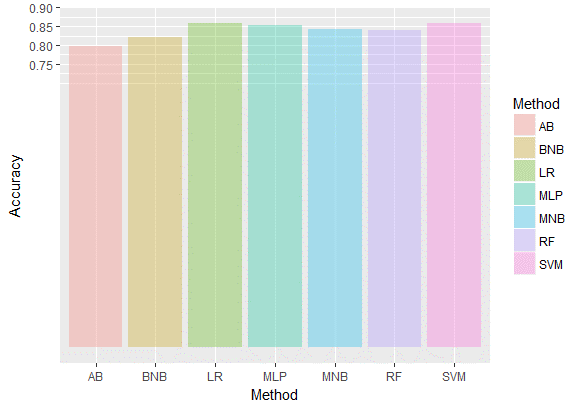
我们没有尝试LSTM的方法,虽然此方法在文本处理中被证明非常实用,因为它的递归参数计算方法可以充分利用前后词的关系,体现出语境意。不过考虑到我们使用的是n-gram的TFIDF方法,已经表现了词组所体现的语境含义,因此,我们此处没有再重复利用这一特征。
从以上对比图可以看出,逻辑回归与支持向量机的分类效果是最佳的。逻辑回归在二分类中表现通常不错。文献中表明支持向量机通常是最适用于情感分析的,但是需要样本量足够大。我们认为可能是由于我们的样本量还不是特别够,因此支持向量机的效果没有比其它方法好太多。
多项朴素贝叶斯的效果比伯努利朴素贝叶斯要好。此处的多项和伯努利并非指分类的数量,是分成两类还是多类而是指变量的取值。伯努利朴素贝叶斯指的是在输入矩阵中的值只能取0/1变量,该词(词组)在本文中出现就取1,否则取0;而多项朴素贝叶斯中是用出现频率进行计数的,及出现次数越多取值越大。伯努利朴素贝叶斯由于舍弃了一个词(词组)出现次数的信息,因此分类效果会降低。
适应自举法和随机森林都是决策树的变种,虽然已经比最普通的决策树效果好,但是仍然表现不佳。原因可能在于,我们输入的TFIDF矩阵的维度过高,要进行准确的分类需要较多的树才能进行。尤其是适应自举法,需要很多分支才能逼近其球形边界。
多层感知器主要用于解决上述问题。它将一个极高维的向量映射到一个较低维的向量,即隐层的维度(此处我们选取100)。之后,再利用一个全连接层对其进行分类。这种方法也得到了一个较高的准确率,超过了85%。但是,可能由于在映射过程中可能有信息损失,因此其效果也没有超过逻辑回归和支持向量机。
9 讨论
9.1 整体准确率不是很高的原因
我们最佳的分类器——逻辑回归——的准确率也才刚刚超过85%,在情感分类的二分类问题中不算很高。我们认为有以下两种可能的原因。
首先,我们用于训练的标签并不是同一个人标注的,而是由不同用户再经过亚马逊食品购买体验之后自己打的分数。但是这其中就会涉及到不同人打分标准不同的问题。面对同样质量的食品,做出了相同的评价,但有些人可能会打4分,而有些人只会打3分,就被分到了正负两个不同的类别里。这就造成了我们的训练标签标准不统一的问题,可能进而影响了我们分类的准确性。
另外,3分的评论还是很难进行分类。虽然我们通过词云观察得到,3分评论大多数是负面的,但是仍然不排除还有很多偏正面的评论存在。我们将负样本中的3分评论全部删除,再次用最佳的逻辑回归分类器进行分类,发现准确率提高到了90.85%。由此可以看出,3分评论确实会混淆分类,尤其是3分常常是上述第一点所说的评分标准不同最易造成打分交叉的分数。
9.2 Twitter评论分类
我们又扒取了30条Twitter的食品评论进行分类,其中包含17条正面评价和13条负面评价,以验证我们的分类器在不同场合的分类效果。Twitter上的食品评论样例包括:
我们用最佳分类器逻辑回归进行了分类,得到了86.67%的正确率,可见分类效果还是非常好的。
9.3 多分类
我们尝试将3分评论划分为“中性”评论进行三分类得到如下结果: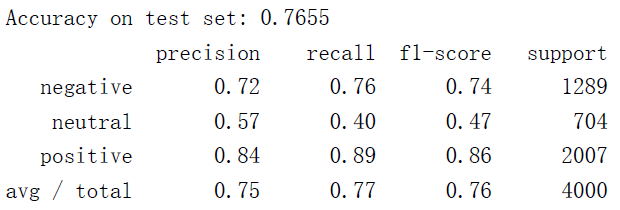
可以看出,分类效果比二分类要差很多。尤其是中性评论非常容易被划分为其它两类,负面评论也很容易被分错。
不过,从三分类的结果中,我们可以进一步验证之前的猜测。加入了第三类之后,正面评价的分类效果没有受到太大影响,但是负面评论受到的影响较大。由此说明,3分评论还是包含负面评论比较多。但是由于正面评论的存在,导致3分评论并不能直接被划入负面评论。因此,我们的二分类器和多分类器的效果都没有达到90%。
10 未来工作
虽然Word2vec不能直接用于情感分类,但是Tang D [6]等通过标注一句话的正负情感来格外强调同一类词的正负性。这种方法重新利用了Word2vec的优势,及可以将一个高维向量映射成低维的,就避免了维数过高带来的问题。
另外,无监督的分类方法也可以用于情感分类。通过提取某些正面和负面的词的特征,判断一篇文章是包含正面情感特征更多还是负面情感特征更多,借此来进行分类。