本文选自清华大学统计学研究中心开设的统计学辅修课程《数据科学导论》优秀学生成果
小组成员:
姜紫煜(清华大学工业工程系14级本科生)
谢禹晗(清华大学工业工程系14级本科生)
高代玘(清华大学工业工程系14级本科生)
王 璐(清华大学工业工程系14级本科生)
指导教师:俞 声
一、引言
我们常说“一见钟情”,但又是什么因素导致了一见钟情呢?哥伦比亚大学的一项基于一次“快速约会”结果的实验数据给我们提供了丰富的研究背景。利用一些数据科学中基本的数据处理手段以及R中的可视化工具,我们获得了许多有趣的结论。
二、数据清洗
此数据集原本有195列数据。但是考虑到我们的目标是预测两人配对成功的概率,其实大部分变量并没有意义。因此,我们对变量进行了一定的筛选。首先,我们通过常识选出了以下69个可能存在相关性的变量:
- 参与者的编号,包括第几轮以及在本轮中的编号
- 参与者与同伴的基本信息,如年龄、职业、家乡等
- 是否配对的结果
- 同伴对该参与者的6项打分
- 该参与者自己认为这6项指标是否重要的打分
- 同伴对这6项指标的重要性的打分
- 该参与者自己对自己这5项指标的打分(除去share的指标,因为这个是描述约会双方的兴趣是否相同的打分)
- 该参与者认为其他人如何对自己这6项指标的打分
- 对17项活动的爱好程度
得到的这69列数据中,有一些数据有所缺失,因此进行了针对性的数据清洗。
(一)同伴对该参与者6项指标的打分的缺失
我们通过观察,发现6项指标不是同时缺失的。而如果直接删除所有带空数据的样本,就会删掉1347条数据。考虑到一共只有8378条数据,我们选择采取填充的办法。 尝试用同一轮中其余9个人的平均值来对第10个人的缺失值填补,但发现均值通常不是整数。而在后续的决策树与分类的过程中,可能需要打分作为factor,因此最终选择取其余9个人的中位数来填补。
(二)iid(该参与者在整个活动中的中编号)的缺失
在总结中位数时,我们发现总行数比iid最大值少1,没有iid伪118的参与者。因此在填充时,要注意用iid而非行数匹配。
(三)id(该参与者在该轮中的编号)的缺失
通过summary函数发现id有一个缺失,其对应的iid为552。列出所有iid为552的样本,发现id应为22。因此在缺失处填上22即可。
(四)参与者自己对自己5项特质的打分的缺失
观察发现,这5项特质的打分总是同时缺失的,说明这是由于在该轮中没有要求参与者对这个项目进行打分。通过计算,发现一共只有105个样本缺失该变量,因此我们选择删除这105个样本。
(五)参与者的年龄与同伴的年龄的缺失
通过对比iid,发现缺失年龄的参与者与缺失年龄的同伴恰好都是同一批人,因此无法对应填补。又因为用年龄的中位数补空可能造成极大的误差,而实际缺失年龄的样本又不是很多,因此,我们选择删除这一部分样本。
三、数据的探索性分析以及数据可视化
首先,我们使用一些基本的统计量及图表来描述参加这次“快速约会”的志愿者的年龄、性别、居住地、教育及工作背景等信息。
(一)年龄和性别
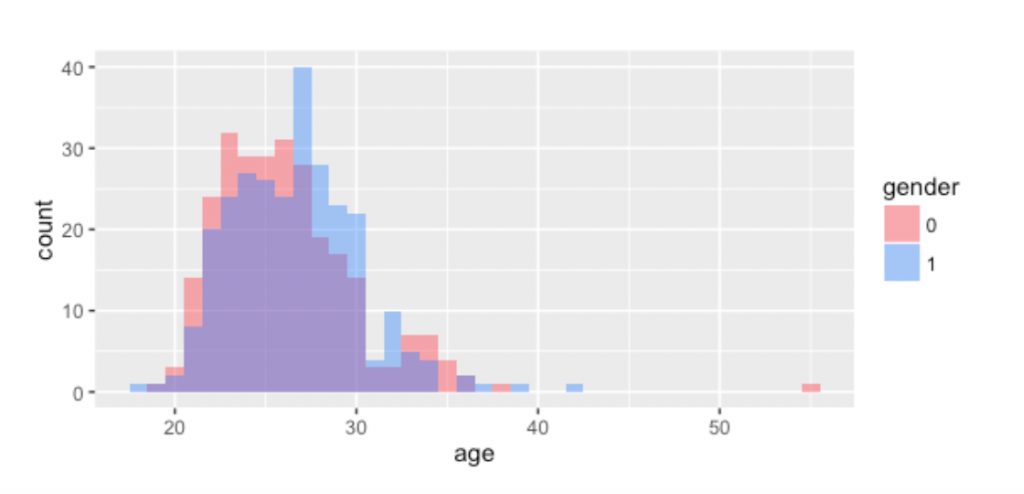
下图以直方图的形式描述了各个年龄段参加约会的志愿者的年龄组成。我们可以看出(1)参加约会的女性和男性的年龄分布基本是相似的,(2)志愿者的年龄大致分布在20岁~30岁之间。
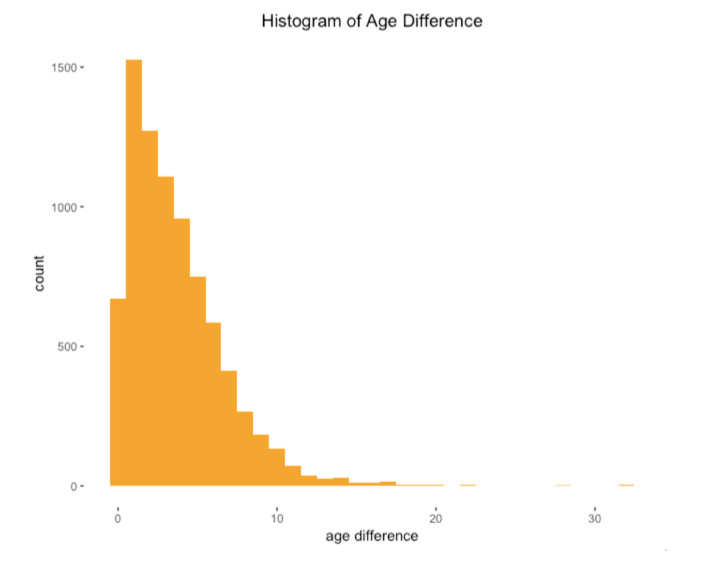
基于常识我们猜测年龄差异可能对约会产生较大的影响,所以我们决定绘制直方图来展示配对成功的参与者的年龄。从图上我们可以看到参与者之间的年龄差在1岁到5岁之间的时候配对成功率较大。但这项研究的大部分参与者是年龄相仿的大学生,所以我们还不能得出年龄相近则配对成功率大的结论。
(二)志愿者的出生地分布
在这个数据集中,大多数的志愿者都来自美国,为了显示方便我们仅仅绘制了美国的部分地图以反映志愿者出生地分布(地图由maps包绘制)。
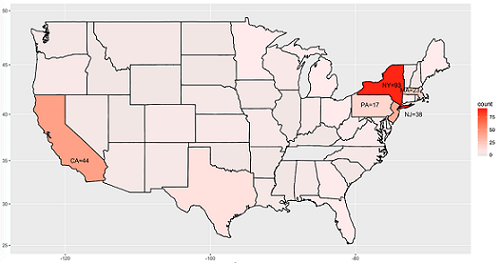
图中可以看出,人数最多的五个州依次是纽约州、加利福利亚州、新泽西州、宾夕法尼亚州和马萨诸塞州。
(三)民族背景
下图以直方图的形式展示了参加约会的志愿者的种族组成。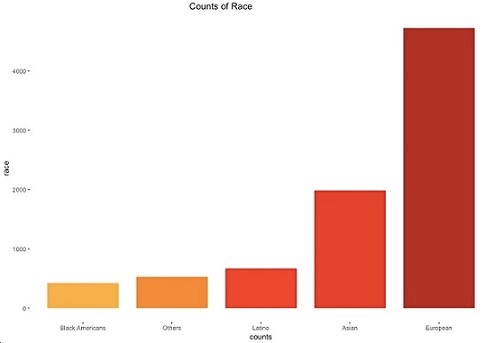
同时,我们还用网络图的形式呈现了配对成功的情侣的种族背景(由R的iGraph包绘制)。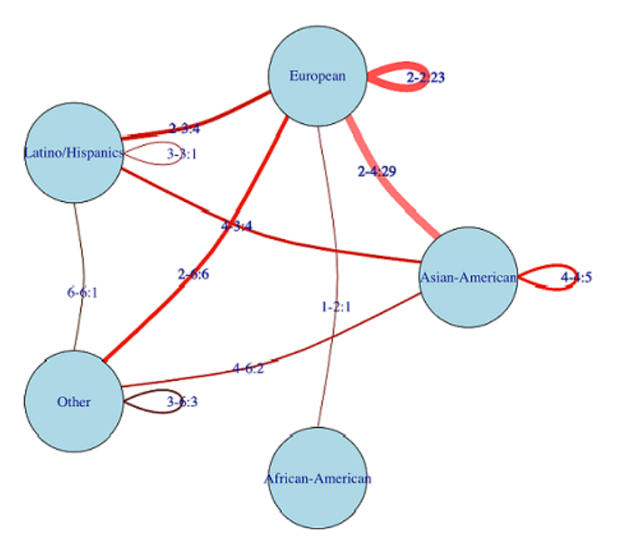
种族背景
图中以圆圈和线的形式标注了各对情侣的种族来源。
(四)职业与教育背景
首先,我们根据志愿者填写的职业信息合并同类职业,并画出频度直方图。我们发现“business”出现的频率最高,符合很多人在经商的现实。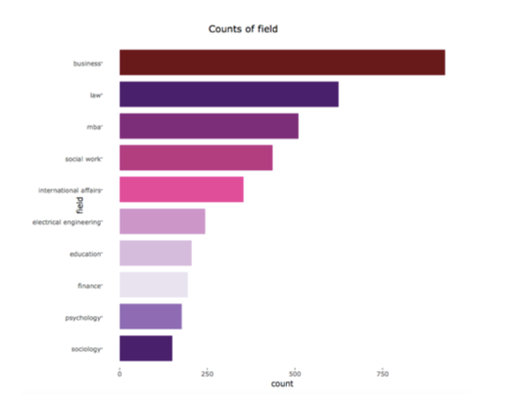
数据集中的职业、教育信息多以非结构化文本的形式呈现。为了更好的展现这一信息,我们采用了词云图的形式体现志愿者们的教育背景(主要为本科就读的学校)以及从事的职业和相应的频率。


从图中可以看出,许多参加本次“快速约会”的志愿者来自美国名校,从事行业也多为法律、商业、学术界等。可谓是“高帅富”、“白富美”也需要担心人生的头等大事啊!
(五)可视化交互:R-Shiny Dashboard
我们选取R中用于可视化的Shiny Dashboard 包将我们的结果进行可视化处理。选取Shiny Dashboard作为可视化工具的原因如下:
- 在课程中,我们已经学习过Shiny的应用,Shiny Dashboard可以帮助我们让我们在Shiny的基础上继续探索R中用于可视化的工具。
- Shiny Dashboard可以包含多个子页面,有助于我们结构化的展示结果。
- Shiny Dashboard可将模型预测部分进行交互化展示。
四、数据处理中遇到的问题
- 许多文字的输入不慎规范。我们并没有直接对数据进行操作,而是取样观察了部分数据,可以看出许多数据的录入不甚合乎规范。比如“新泽西州”(New Jersey),许多人可能会有不同的表述,诸如”New Jersey is my hometown, while I currently live in NYC”(我出生在新泽西但我现在生活在纽约)等等。
- 文字的错误输入。由于部分数据由人工打字录入,存在一定几率的拼写错误。
- 重叠的语义概念。在利用分词功能处理字符串的功能时,可能出现由于拆分词组导致原本具有特殊含义的词语被拆分导致原有含义丧失(如’industrial’(工业)与’engineering’(工程)和‘industrial engineering’(工业工程))是不同的概念(工业工程应属于工程学科的一种),而当我们单纯将所有词组拆分时则得不到该分类。
为了获得较为合理的文字处理结果,我们首先用R的分词处理功能获得了我们感兴趣的关键词,解决了第一种问题;对于高频词我们使用了正则表达式检验可能发生的错误输入,还利用数据挖掘的概念探寻可能存在的相关连词汇,以减少上述第三种错误发生的可能。
五、变量间的相关性分析
下图展示了影响配对成功的重要因素的相关性,冷色调代表正相关,颜色越深代表相关性越大。我们发现“喜欢程度”这个因素与“兴趣爱好重合度”,“外在吸引力”,“幽默程度”都有很强的相关性,为后续模型的变量选择提供了依据。此外我们发现,作为评判方的志愿者在“聪明程度”和“野心程度”、“真诚度”,“幽默程度”和“兴趣爱好重合度”、“外在吸引力”也有明显相关性。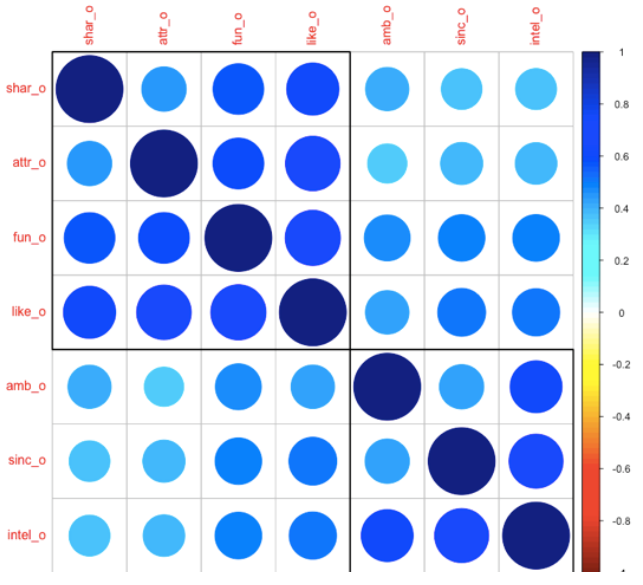
六、决定性因素分析及预测
- 决策树模型一
我们用决策树的方法尝试找出影响配对搭档的决策的最重要的影响因素。我们使用清洗好的数据,排除部分无效信息后进行建模。我们发现是否配对成功很大程度上取决于搭档的“喜欢程度”,这是符合常理的。但由于“喜欢程度”是一个包含很多复杂因素的变量,所以我们对模型进行优化,去除类似“喜欢程度”这样的可能与其他变量有很大相关性的复杂变量。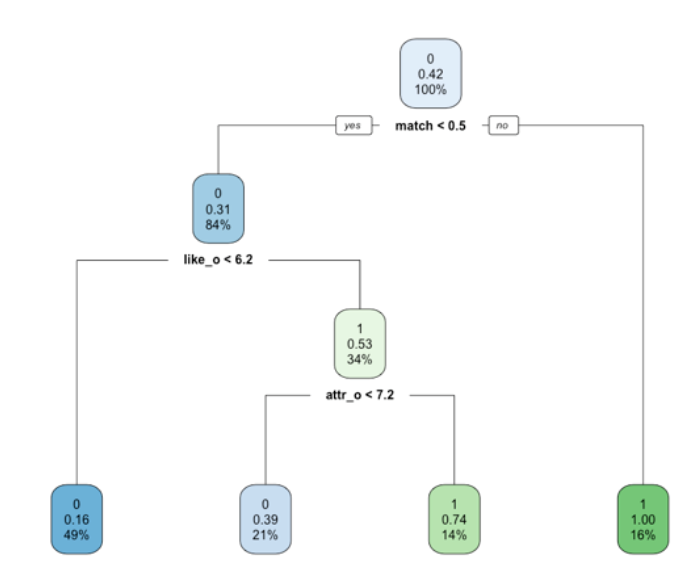
调整后,我们得到下图所示的模型。搭档对于志愿者吸引力的评分很大程度的影响能否配对成功。此外,适度的幽默也有助于“牵手”成功。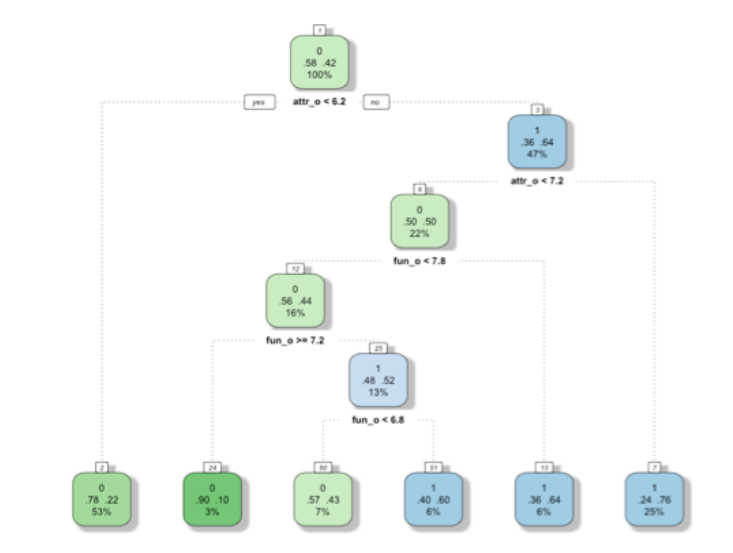
- 决策树模型二
为了预测两个参与者配对成功的概率,需要将二者的特征和相互关系同时放入模型中进行预测。因此,我们将两个参与者的对于6个特质互评的分数、及分数的差的绝对值同时放入决策树模型中。
可以发现,最重要的影响变量依然是“外在吸引力”和“幽默程度”。但与之前模型得出的结论不同的是,“兴趣爱好重合度”也成为了重要的影响因素。这很符合我们的常识,及两个人只有“三观一致”的时候才更容易在一起。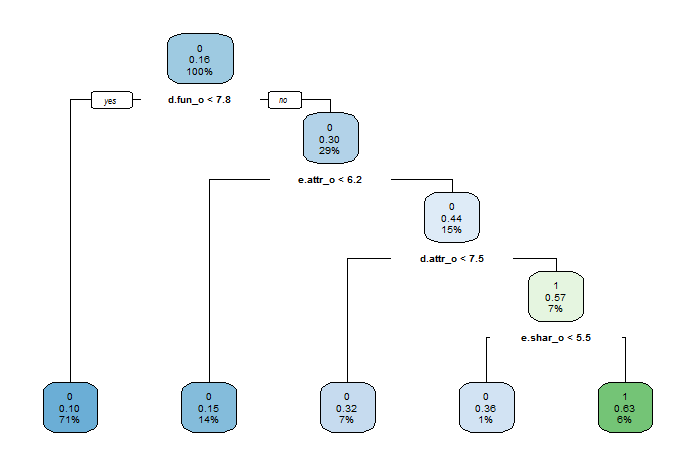
我们通常认为两个人打分的差异性也会有影响,即各方面特征都较为相近的人才更容易在一起。但是这一点在模型中却并没有体现出来,各方面打分的差的绝对值最后没有出现在决策树模型中。我们认为这可能是由于两人的差异不能简单地通过差地绝对值来体现,可能有更复杂地表示形式,因此导致变量设置不当。
七、牵手成功的预测
运用以上的决策树模型,我们希望对还未参加活动的人在该活动中能否找到意中人进行预测。但是这只能预测搭档能否看上这个参与者,而不能预测两人能否最终牵手成功,因为搭档的情况还未知,不能保证此参与者也能看上他的搭档。
通过决策树模型,我们发现一个人认为他人对自己的看法与他的搭档最终是否看上他了并没有绝对联系,这意味着人们认为他人对自己的认知通常是错误的。因此,我们假设一个参与者可以通过以往的经验得到他人对自己的打分,并用这个打分进行预测,判断自己有没有必要去参加一场快速约会。
以下两个例子说明了不同的预测结果:
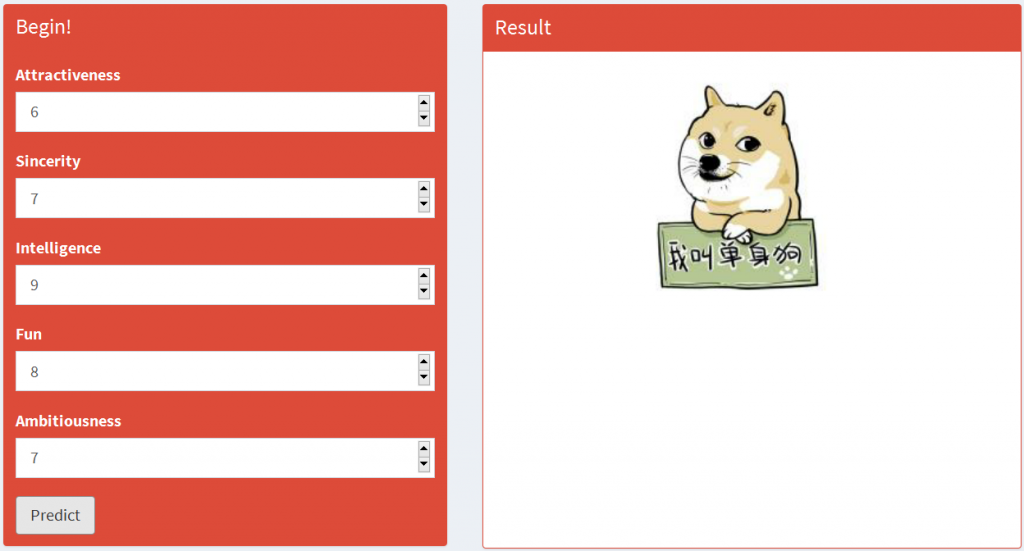
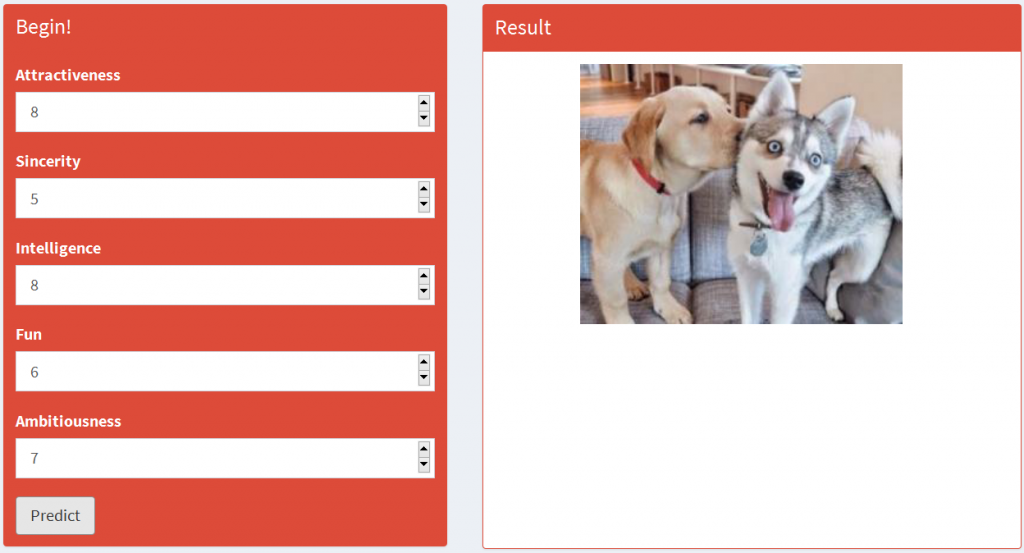
八、结 论
我们的决策树模型提供了如下几个有趣的结论:
- 受吸引程度依然是配对成功最重要的前提。虽然现在大家常常会说自己“不看脸”,但其实内心还是很诚实的嘛!
- 兴趣广泛的人也相对更容易配对成功。
- 具有中等幽默程度的人在约会中占有一定优势。
总的来讲,虽然“颜值”(attractiveness)的确对约会是否成功起到了主要作用,我们仍然无法忽视个人爱好(share)以及幽默感(fun)的重要性。所以,对于希望找到另一半的各位,不仅要维持一个良好的外部形象,追求内在也十分重要哦!
九、总 结
本项目中曾使用过的研究手法和展示手段:
- 数据清洗
- 描述性统计量分析及相关图表绘制
- 相关矩阵等统计建模
- 决策树、主成分分析等数据挖掘技术
- 数据可视化:地图、网络图、词云图绘制
- 交互式操作界面的搭建
本项目使用R语言进行数据处理和展示,主要使用的扩展包如下:ggplot2& ggplotly (数据可视化绘图)、shiny(交互界面搭建)、igraph(网络图)、maps(地图)、wordcloud2(词云图)、rpart(决策树建模绘制)
参考文献:https://www.kaggle.com/annavictoria/speed-dating-experiment(数据集来源)
参考书目:Winston Chang,《R数据可视化手册》. 人民邮电出版社