TopWORDS:一个高效的无监督文本分词方法
方法简介
随着数字化文本数据的大量产生,对提取文本信息工具的需求与日俱增。TopWORDS (Top-down WORd Discovery and Segmentation) 是由清华大学统计学研究中心邓柯教授实验室研制推出的一套无监督的文本分词方法,能够同时实现高效的文本分词和新词发现。特别地,它在领域特定、包含大量未知或不规则的词语、短语、术语的中文文本处理中卓有成效。
当文本与训练集有很大不同时,TopWORDS往往能超过常用的基于有监督学习的方法。
此外,通过将每个单词视作一个“汉字”,TopWORDS还能被直接应用于英语等字母语言的文本,在固定表达、习语、特殊名称等发现的下游分析中提供丰富的信息。
在线演示
点击进入:[TopWORDS在线演示平台]
R包安装
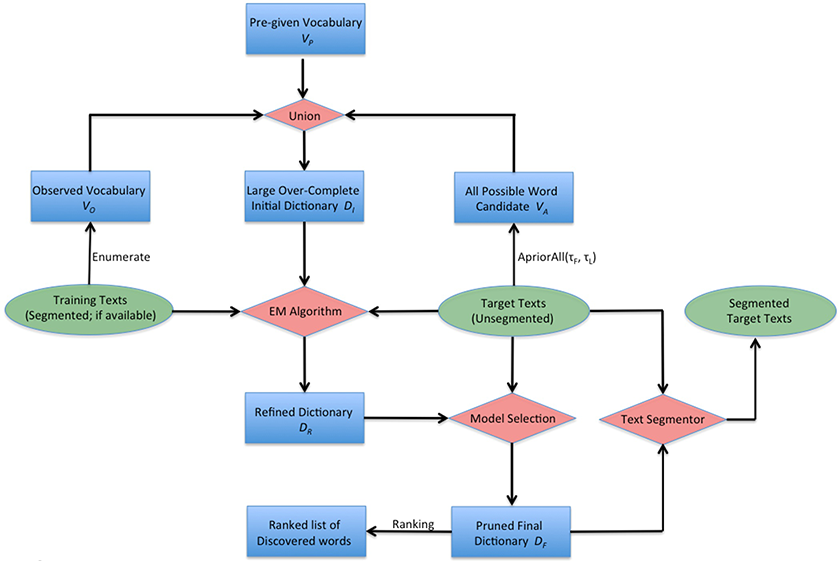
TopWORDS can achieve efficient “word discovery” and “text segmentation” simultaneously for any text sequence encoded in utf-8. It's particularly useful for processing domain-specific Chinese texts which contains a large number of unknown or irregular words, phrases and technical terms. In case that the target texts are very different from available training corpus, TopWORDS often outperforms popularly used methods based on supervised learning. The method can also be readily applied to English and other alphabet-based languages for discovering regular expressions, idioms, and special names by treating each English word as a character, which can be more informative for downstream analyses.
The figure below illustrates the architecture of the TopWORDS algorithm. More details about the approach can be found in our paper.
Reference: Deng, K., Bol, P. K., Li, K. J., & Liu, J. S. (2016). On the unsupervised analysis of domain-specific Chinese texts. Proceedings of the National Academy of Sciences of the United States of America, 113(22), 6154–6159. http://doi.org/10.1073/pnas.1516510113
Besides, four demo data files in zip format are provided for download:



